Data Analytics Simplified
A Toolkit for Automated Workflows and Operational Efficiency
Imagine that you are the host of “Help! I Wrecked My House!” But instead of navigating through the debris of a DIY home renovation gone awry, you’re diving headfirst into a chaotic world of spreadsheets, rogue data streams, and a jumble of mismatched tools. The mission? To declutter, organize, and automate workflows, laying down the solid groundwork necessary for efficient reporting and data science. This is the life of a data analytics engineer.
Here on this blog, I’ll share insights, tips, tricks, and a robust framework designed to tackle the ever-evolving challenges of data engineering and analytics. Given that every company and initiative comes with its unique set of requirements, and considering the dynamic nature of data, you won’t find any one-size-fits-all guides here. Instead, I aim to share my thought process and problem-solving strategies to help you identify the most effective processes and tools for your projects.
You might find yourself here because you:
- Scaling Spaces: Just like a family outgrowing their starter home, your data needs have expanded beyond your current infrastructure’s capabilities. You’re at a crossroads, wondering whether to “love it” by upgrading your existing setup or “list it” by seeking out new solutions.
- Faced Analytics Ambitions: Perhaps you’ve invested heavily in analytics, hoping for transformative insights, only to find your initiatives stalling or underdelivering—much like the projects on “Rico to the Rescue.”
- Stepped Into a New Domain: Or maybe you’ve just stepped into the vast world of data analytics, seeking advice and tips on how to navigate this complex yet thrilling landscape.
No matter your situation, I’m here to equip you with the essential tools for your data analtyics toolkit, tailored specifically for the lean tech startup environment. Welcome!
Recent Posts
-
Deploy Your Next Flask App Instantly and for Free Using Replit
Replit is a free tool that makes it easy to write Flask code and deploy it instantly. They handle of all the underlying infrastructure, allowing you to focus on building and refining your app without worrying about setup and maintenance.
-
A Short Practical Guide to Window Functions in SQL
A window function allows you to concisely compare rows in a single table.
-
How to Convert a Seconds Column to Minutes and Hours in Pandas
In this post, I’ll walk through how to convert a Pandas column that is in seconds and convert it to a datetime or a formatted string.
-
Things to do – Flask app
This is a little Flask web app I made to get recommendations for things to do when traveling.
-
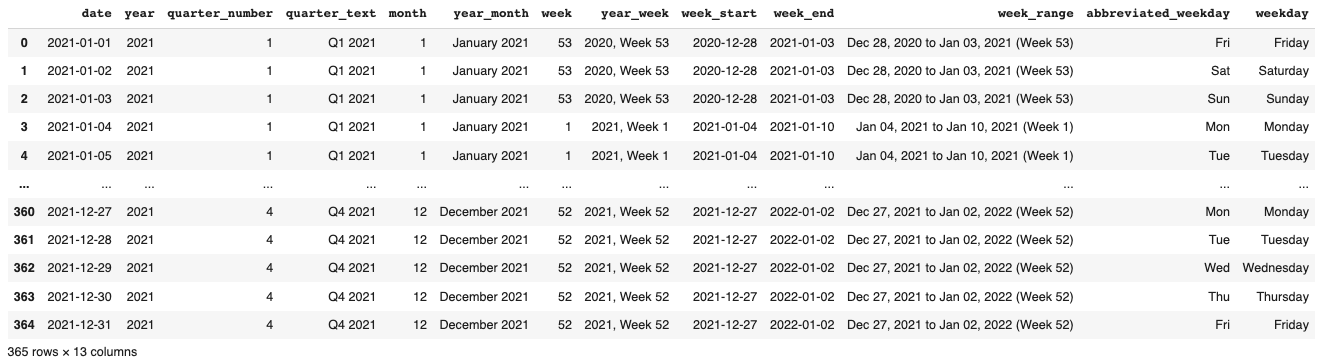
How to Dynamically Generate a Date Dimension Table using Python Pandas
The Pandas package in Python allows you to generate a list of dates dynamically and then extract their attributes with various datetime functions.
-
How to Dynamically Add new Rows to a Pandas DataFrame
This is a little trick I used to append new rows to a Pandas DataFrame. This method is similar to appending a new item to a list.
-
What is Data Engineering?
A Data Engineer’s primary focus is to assist companies in scaling their reporting capabilities beyond the limitations of spreadsheets. Automated systems are implemented to replace manual processes and import data from various sources, which is then transformed for easy visualization or use in data science models.
-
How to Dynamically Format Pandas DataFrame Columns to be Database and Parquet Ready
Pandas allow for almost anything as a column header and I’ll show you how to get your columns parquet and database ready.
-
How to Compare the Schema Between Two Pandas DataFrames
Having consistent schemas between two Pandas DataFrames is essential when saving to Parquet and for merging operations.