
Intro
For a long time, data engineering in most organizations looked a lot like plumbing on a building that never stopped changing.
Every new business request meant another line to run. One from the application database. Another from Salesforce. Another from some newly important API. All of it eventually tied back to the same utility room: the warehouse. Once the data made it there, the reporting layer could be bolted on and the business could finally use it.
And at the time, that was the job.
The work itself was heavy. Pipelines had to be carefully designed, coded, adjusted, and maintained by hand. When a source changed, a requirement shifted, or the plan moved, the line had to be reopened and reworked. Add another connector. Reroute the flow. Patch around the last set of decisions without breaking everything downstream. Building and maintaining the system already took enormous effort, so naturally the role narrowed around the pipe.
But the shape of the work is changing.
Agentic coding environments do more than accelerate code generation. They create a new operating environment for the function itself. Instead of forcing every meaningful step through the same narrow path from source system to warehouse to BI layer, data teams now have a place to integrate systems, inspect data, prototype interfaces, deploy services, read logs, and iterate across the whole build in one connected loop.
That shift is bigger than speed.
The old job was building and maintaining pipelines. The new one is orchestrating outcomes across data, code, interfaces, and infrastructure.
That changes the role at a leadership level. The function is no longer limited to keeping the plumbing running through an expanding building. It can operate more like a general contractor: still technical, still close to the structure, but increasingly responsible for how the whole site comes together, what deserves permanent infrastructure, and where value can be delivered faster with lighter-weight solutions.
The pipes still matter.
They are just no longer the whole job.
When the Function Got Pulled Into Plumbing
Once the first few lines were in, the role had a way of collapsing into maintenance.
This was not just about connecting one source and moving on. It was about keeping pressure steady across the whole building. A new table showed up in the application. Salesforce changed. A stakeholder wanted a new KPI. Another team needed a dashboard. None of those requests lived in isolation. Each one had to be worked back through the same walls, the same utility room, and the same set of decisions already buried behind drywall.
That is what made the old operating model so consuming. It was not just the initial install. It was the constant rewiring.
The traditional data path was narrow but familiar: pull the data, run it through ETL, land it in the warehouse, shape it for reporting, and keep the whole system from springing leaks every time the plan changed. Low-code tools helped get the first rooms online faster, but they also had a way of turning temporary fixes into permanent structure. What started as a clean run of pipe slowly became a maze of connectors, patches, and awkward bends that no one wanted to disturb.
So naturally, most of the function's bandwidth stayed there.
When every change is manual, teams optimize for what they can keep running. They focus on the sources they already know, the reports the business already depends on, and the parts of the building they can afford to open back up. There is not much room left for exploration, redesign, or experimentation. The operating model narrows around the pipe because the pipe is already consuming the capacity of the team.
That was the hidden cost of the old model. It was not just one-way. It was all-consuming.
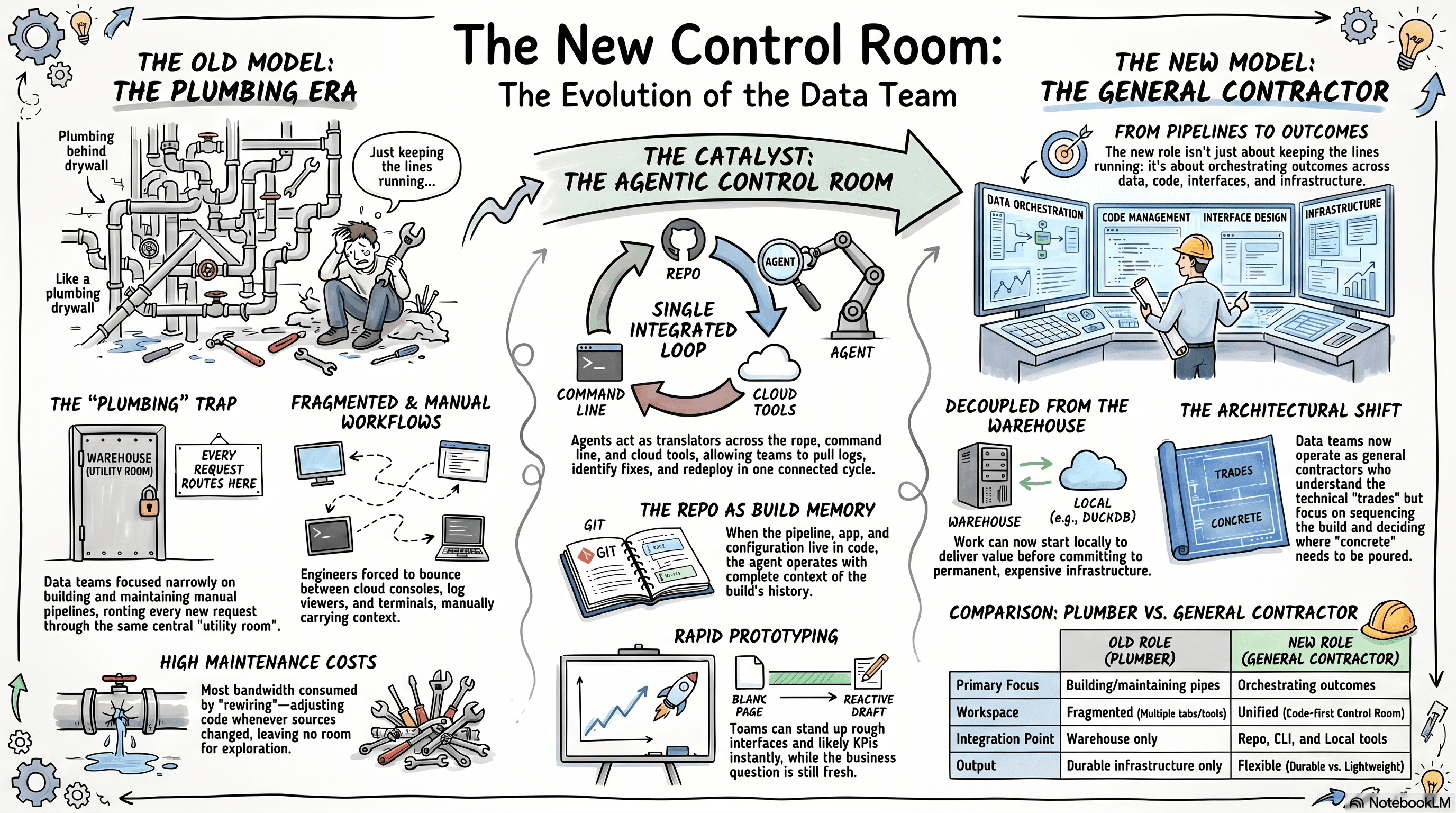
A New Control Room
The biggest change is not that agents help teams write code faster.
It is that data teams finally have a new place to work.
For a long time, the warehouse was more than storage. It was the only room where everything could really meet. If an organization wanted to pull systems together, shape the data, test the output, and hand something useful to the business, the warehouse was where that work had to converge. And if something broke outside of it — in AWS, in Azure, in GCP, in some SaaS API, or in the BI layer — the team was back to bouncing between cloud consoles, log viewers, editors, terminals, and dashboards trying to stitch the system together by hand.
That fragmentation was part of the operating model.
Modern data teams live across too many systems at once — Python, SQL, cloud UIs, log viewers, infrastructure config, and the BI layer — each with its own syntax and workflow. Even when the architecture was understood, the work still had to be translated constantly.
That is what starts to change in an agentic coding environment.
Instead of treating the warehouse as the only place where the pieces can come together, organizations now have a code-first control room sitting in the middle of the repo, the command line, the cloud tooling, the application code, and the data itself. The agent becomes a translator across all of it. It can read the Python, work through the shell commands, understand the cloud syntax, inspect the logs, reason about the data, and move between those layers without forcing the team to manually carry context from one room to the next.
That changes the loop.
Before, if something failed in the cloud, the cycle was painfully manual. Open AWS. Find the service. Pull the logs. Translate the error. Open the editor. Make the change. Deploy again. Go back and check. Maybe update a configuration manually. Maybe discover the problem was somewhere else. Repeat.
Now, once the command-line tools are connected, the loop tightens up. Pull the logs. Summarize the failure. Identify the likely fix. Change the code or configuration. Deploy again. Read the new logs. Repeat until the system settles.
That is not just faster debugging.
It is a different operating model.
The team is no longer walking the building room by room trying to figure out where the issue lives. It is working from a control room that can see the whole floor plan at once.
That matters even more in a multi-cloud world. Most organizations are not living inside one clean stack anymore. They have AWS in one corner, Google somewhere else, Azure where it was inherited, and SaaS tools hanging off the side. Data teams have to move through all of it. That has always been possible in theory. In practice, it meant carrying a lot of fragile knowledge in people's heads: which command works where, which service exposes which logs, which deployment path belongs to which platform, which small syntax rule is going to bite at the worst possible moment.
That overhead starts to come down when the workspace itself can translate.
And the same thing happens on the reporting side.
One of the hardest parts of data work is that the engineering side is usually more defined than the reporting side. Moving data from A to B is deterministic. Deciding what matters, what KPIs belong on the page, what story the data is really telling, and what the first dashboard should even look like is much less clear. Stakeholders often do not know what they want until they can react to something concrete.
That first pass used to be expensive.
Now it is much cheaper to make one.
A team can bring in the data, let the agent take a first look at the shape of it, ask for likely KPIs, stand up a rough interface, and get to something visible much faster. The value is not that the first draft is perfect. It usually is not. The value is that the team is no longer starting from a blank page.
There is something to react to while the question is still fresh.
That matters because so much of the reporting stack has historically lived in heavy UI-driven tools. Those tools helped data teams get started, but they also trapped a great deal of logic inside click paths, hidden state, and one-off design work. Once agents get strong enough to help generate the code, the frontend stops being such a hard boundary. A function with strong backend instincts can suddenly work much more fluently on the interface too — not because it became a frontend organization overnight, but because it finally has a capable translator sitting beside it.
That is where the repo starts to matter even more.
The more of the workflow that lives in code, the more of the system the agent can actually operate. If the data pull is in code, the transformation is in code, the app is in code, the deployment is in code, and the history lives in Git, then the agent can work across the full loop. It can make a change, deploy it, read the logs, revise the code, and keep going with the full context in front of it.
That is what makes the workflow genuinely agentic.
If the process still requires screenshots of a report, pasted prompts, copied code, and manual click-through deployment steps, that is not really a new operating model. That is just the old model with some speed layered on top.
Helpful, yes.
But not the same thing.
The real shift happens when the whole build can live in one shared working memory.
That is why tools like Git matter so much here too. The repo becomes the memory of the build itself, housing the pipeline, app, configuration, deployment path, and iteration history. This shared working memory makes the loop more capable.
And once that loop exists, something else changes too: the warehouse stops being the automatic starting point for every useful thing.
A lot more can happen locally now. With a tool like DuckDB holding the data, a lightweight app showing the output, and an agent helping stitch together the backend, frontend, and deployment logic, teams can do serious work before deciding what deserves permanent infrastructure.
That does not make the warehouse irrelevant.
It just means it is no longer the only place where data work becomes real.
That may be the biggest shift of all.
The warehouse used to be the default place where integration and orchestration had to happen. Now there is a new control room for that work — one that can sit above the clouds, above the UI layers, above the old handoffs, and let the function operate much more directly across the whole system.
From Pipeline Team to General Contractor
This is where the role really changes.
The old job was building and maintaining pipelines. The new job is orchestrating outcomes across data, code, interfaces, and infrastructure.
For a long time, most data functions had to stay close to the pipe. Pull the data in. Shape it. Keep it flowing. If the business needed something new, the answer usually meant extending the same system one more time. Another source. Another transformation. Another report. Another line run back to the same utility room.
The work stayed in the plumbing because the plumbing already took everything.
Now the value starts higher up the build.
The function still needs to understand the trades. It still needs to know what breaks when the wrong wall gets opened and where the load-bearing structure is. But the job is no longer just hand-routing every line. It is deciding what needs permanent structure, what can stay lightweight, what belongs in the warehouse, what can live locally, and how the whole site should come together.
That is a general contractor's job.
A general contractor does not stop understanding the work. The role changes because the measure of value changes. The point is no longer doing every task by hand. It is looking across the whole site, sequencing the trades, deciding what gets built now, what waits, and what is not worth pouring concrete for yet.
That is what data work is starting to look like.
A modern data function can now move across the full loop — data access, first-pass interface, deployment, operational feedback, and iteration — without handing the work off across disconnected tools and teams. The job is no longer just to install the plumbing. It is to get the room working.
That changes the kinds of answers the function can give.
Sometimes the right move is still a durable pipeline into the warehouse. Sometimes it is a lightweight local application backed by DuckDB. Sometimes it is a small cloud function and a report. Sometimes it is just enough structure to answer the question without turning it into permanent architecture too early.
That is the shift.
The role gets broader. More architectural. More product-minded. More operational. Data teams are not just moving data anymore. They are shaping how systems, people, and decisions connect around it.
The Job Got Bigger
None of this means the warehouse stops mattering.
The pipes still matter. Durable pipelines still matter. Clean models still matter. A well-built utility room still matters. There is still a great deal of work that belongs in permanent structure, and there always will be.
What changes is that it is no longer the only place where useful work can happen.
For a long time, the warehouse had to be the center of gravity because it was the only place where data could really come together, be shaped, and become something the business could use. That is why so much of the role narrowed around getting data into that room and keeping it flowing once it was there.
Now there is another center of gravity.
A code-first, repo-backed, agent-assisted workspace gives data functions a new place to integrate systems, inspect data, build interfaces, deploy services, read logs, iterate on designs, and decide what deserves to become permanent structure. The work can still end in the warehouse when that is the right destination. It just does not have to start there every time.
That is why this shift matters.
This is not about replacing data teams with AI. It is about expanding what the function can reach.
The old data engineer kept the line running.
The new one runs the site.
And that feels like the real opportunity in front of data leaders now.
For data leaders, that means the question is no longer just how to keep pipelines healthy. It is how to design a function that can learn faster, build lighter, and decide more deliberately where permanent structure is actually needed.
Not less engineering.
More range.
More leverage.
More room to build.